rubrics
Locked rubrics: why a single rubric beats a smart AI
When you ask ChatGPT to grade 30 essays, you don't really get one grader. You get up to 30. Here's why locking the rubric across the whole batch matters more than any model upgrade.
 Enzo · April 28, 2026 · 9 min read
Enzo · April 28, 2026 · 9 min read
I taught for ten years before I built a grading tool. Across most of those years the worst part of the job was the same. Friday night, a stack of papers, and the slow erosion of standards from paper one to paper thirty. By paper fifteen I was tired. By paper twenty-five I was generous. The first kid in the stack and the last kid in the stack were not graded by the same teacher.
Most teachers I know have a version of this story. It's such a normal part of the job that it has a name in the assessment literature: rater drift. And it's the single biggest reason I'm sceptical of "just use ChatGPT to grade your papers" advice. Asking a chatbot to grade thirty papers in thirty separate prompts gives you thirty graders, not one. You don't escape drift. You just hide it.
The drift problem isn't a teacher problem
For a long time we treated grading inconsistency as a willpower issue. Drink more coffee. Use a clearer rubric. Take breaks. The honest research says no amount of discipline fully fixes it. A 2026 study comparing AI grading models against multiple human raters found only moderate agreement between human raters themselves on argumentative essays. The AI systems, by contrast, were internally more consistent than the humans, but didn't agree with the humans either. Two different problems, both real.
So if you're already worried about consistency between you and the teacher next door, the right reaction to AI grading isn't "great, problem solved." The right reaction is "how does this AI stay consistent with itself, and how does it stay consistent with my actual rubric?" That part gets skipped in most demos.
Same prompt, different answer, even at temperature zero
The model behavior matters here. You can set a model to its most "deterministic" setting (no creative randomness, just give me the most likely answer) and still get different outputs every time you ask the same question.
In a now-famous experiment, the team at Thinking Machines Lab ran the same prompt one thousand times against the same model with all the dials turned to maximally deterministic. They got eighty different completions. The most common one appeared seventy-eight times out of a thousand. All thousand completions matched perfectly for the first 102 tokens, then started to drift. Some said "Queens, New York." Some said "New York City." Same prompt, same temperature, same model, different answers, depending on how the request happened to be batched against other people's requests on the server at that moment.
That's not a bug. That's how big LLMs work. The math behind matrix multiplication produces slightly different floating-point results depending on how operations are grouped together in memory, and the grouping shifts based on server load you can't see.
The team did manage to fix it, by running specially-built kernels that ignore batch size, but at a cost: the deterministic version ran 1.6× to 2× slower than the standard version. No major commercial AI grading product is doing this in 2026. Which means: when you upload thirty papers and ask the model to grade them, the version of "consistent" you're getting is server-load-dependent in the same way your Friday-night grading is end-of-day-dependent.
What "locked rubric" actually means
When I say a rubric is locked, I mean something very specific:
- One rubric is computed once, from the assignment plus a sample paper, before any grading starts.
- That same rubric (the exact same JSON object) is fed into every paper for that batch, alongside the paper image.
- The rubric is shown to you before grading begins, and you can edit it. Once grading starts, it doesn't change.
That sounds obvious. It isn't what most "AI grading" tools actually do. If you grade thirty papers as thirty separate ChatGPT conversations, even with the same prompt pasted in, the model derives the rubric afresh each time. Sometimes it weighs spelling more. Sometimes it gives partial credit on the third question and not the seventh. Sometimes it adds a category you never asked for. Real teachers in a 2026 implementation study reported the AI "took points off for things not in the rubric" and used standards "outside of the students' current skill level." That's not a weird edge case. That's the default when nothing is anchored.
What this looks like across thirty papers
Tamara Tate's research at UC Irvine, surfaced in FutureEd's reporting at Georgetown University, found ChatGPT within one point of a human grader 89% of the time on one batch, but only 76% on another batch of the same kind of essays. Exact agreement was about 40% of the time. So if you handed the same thirty essays to ChatGPT and to a human, you'd expect them to land on the same exact score on roughly twelve of them.
Twelve out of thirty is not bad if the AI is helping you do a first pass on a low-stakes homework set. It is not enough if it's the score the parent sees on the report card. Tate's own recommendation, to other teachers asking her about AI grading: use it for low-stakes purposes only, and ask any vendor pitching you their AI grader two specific questions:
What is the rate of exact agreement between the AI grader and a human rater on each essay? And how often are they within one point of each other?
That's a much more useful test than "is the AI accurate." AI accuracy without a stable rubric is a moving target. Locked-rubric accuracy is a number you can actually compare across vendors.
How a locked rubric changes the day
Most of what makes Sunday-night grading miserable isn't the marking itself. It's the decisions. Should this answer get full credit or partial? Did I give Maria three points for this same answer last week? Was I being too generous on question two? A locked rubric absorbs all of those decisions once, before the grading starts. After that, the AI is just running the same play.
Practically, this means three things change:
- You spend most of your effort on the first paper, not the thirtieth. The hard thinking goes into the rubric. The rest is execution.
- The teacher next door, grading the same assignment, gets the same rubric. The actual scoring object matters more than the prompt. That's the only path I know to consistent grading across sections in the same school, something a 2024 OECD/TALIS survey found schools genuinely struggle with even before AI showed up.
- A parent meeting becomes survivable. When a parent asks "why did Sam get a 7 and not an 8," there is exactly one rubric to point at. Not your memory of how you were feeling at 9pm on a Sunday.
When ChatGPT is fine, and when it isn't
I want to be honest. ChatGPT is great for a lot of grading-adjacent work. Drafting feedback comments. Summarising what a student wrote so you can decide quickly. Catching obvious errors. Generating practice questions. None of that requires consistency across thirty submissions, because none of it goes on a transcript.
ChatGPT becomes risky the moment the score itself is the artefact you're producing. The Gallup/RAND teacher workload survey out in mid-2025 found that three in ten US K-12 teachers were using AI weekly, but grading was the lowest-rated use case. Only 57% of weekly users said AI improved their grading quality "at least somewhat," compared with 74% for administrative work. Teachers know. They feel the drift.
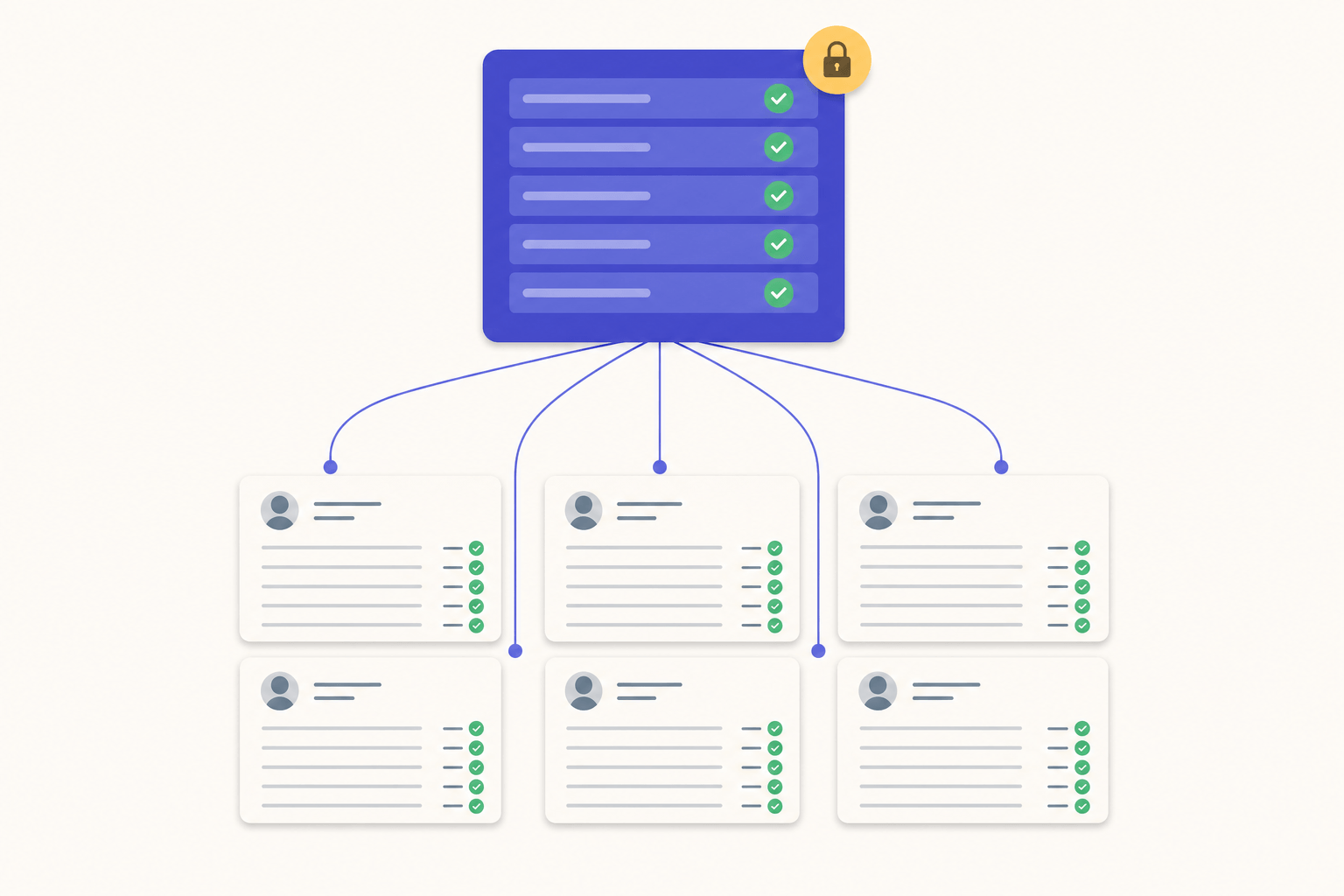
What to ask of any AI grading tool you try
I'd boil it down to four questions. Most products will fail at least one of them, and that's fine. It tells you what kind of tool you're holding.
- Is the rubric computed once per batch, or per paper? If per paper, you're getting drift baked in.
- Can I see and edit the rubric before grading runs? If not, the AI is making pedagogical choices on your behalf that you'll never see.
- Are scores editable after the fact, and tracked as teacher edits? You will need to override the AI sometimes. The tool should make that easy and honest, not buried.
- Does the tool stay private? A surprising number of grading apps store student work to "improve their model." That's a hard no in any school I'd ever taught at. (Grade Coach's policy on this is on the privacy page. Short version: we don't, and we don't sell or share student work either.)
AI is not better than a good teacher. It will probably never be. But a tired teacher on paper twenty-eight is no longer the gold standard either. The bar to clear is whether the AI gives you back the time and the consistency you've already lost, without quietly making the grading drift somebody else's problem. That's all locked rubric means. It's a small idea, and it changes the whole Sunday.
Note on sources: the Thinking Machines paper cited above was published in September 2025; the FutureEd / UC Irvine research was first reported in 2024 and presented at AERA. Where I've cited primary studies older than the rest of the post, it's because they're still the most rigorous public data on the question. Newer commentary almost always points back at them.